La refonte du site Gandi ces dernières années est plus qu’un coup de peinture sur le site web mais également un changement conséquent de l’architecture de nos services.
Sur la précédente version du site, toutes les opérations du site passaient par une API XML/RPC, la même que nous proposons toujours à nos clients. Et tous les produits utilisaient la même API centralisée.
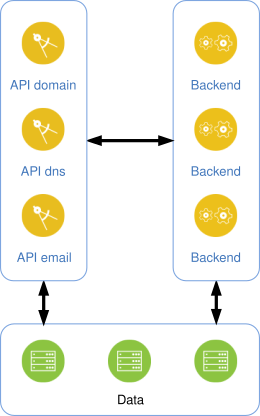
Avec Gandi version 5, nous avons développé une architecture où chaque produit est géré par une API REST spécifique. Nous avons par exemple une API se chargeant exclusivement du DNS, une autre des domaines, et encore une pour les produits hébergement. Ce modèle connu sous le nom « micro services » fonctionne bien et permet à chaque produit d’avancer à son rythme et d’être cloisonné.
Voici un schéma très simplifié de l’architecture, avec des APIs qui communiquent directement avec des services asynchrones ou une ou plusieurs bases de données.
Ces services nous permettent d’offrir une nouvelle API HTTP qui utilise les verbes HTTP et JSON comme format de données. En commençant à travailler sur cette nouvelle API publique, nous avions quelques contraintes :
- N’exposer qu’un seul point d’entrée général.
- Restreindre et transformer les données reçues et envoyées.
- Fournir une documentation claire et à jour.
Pour la réalisation du premier point, nous avions besoin d’une passerelle qui envoie les requêtes pour un certain chemin vers le bon service cible. Par exemple une requête `GET /v5/domain/domains` sera transmise à `http://api-domain.example/v5/domains` (le nom d’hôte est fictif).
La restriction et la transformation des données requièrent toutes deux de pouvoir transformer ce qu’on envoie au service cible et ce qu’on reçoit de celui-ci. Dans tous les cas, il s’agit d’intercepter les requêtes et les réponses et d’y appliquer n’importe quel traitement nécessaire.
Par exemple, si l’API publique peut recevoir ce type données :
json
{
"fqdn": "gandi.net",
"duration": 2
}
Le service cible (interne) reçoit quant à lui, ce format là :
json
{
"domain_name": "gandi.net",
"duration": 24
}
Dans cet exemple, le champ `fqdn` doit être renommé et la valeur de `duration` multipliée par 12. Cet exemple est fictif mais illustre le type de contraintes auxquelles nous somme confrontés.
Enfin, une API n’est rien si elle n’est pas documentée en détails, avec suffisamment d’explications et des exemples. Cette documentation doit évidemment être à jour et refléter l’état courant de l’API, pas celui du mois dernier.
Un format de documentation
Il a fallu choisir un format assez tôt dans le projet et nous avons opté pour RAML. Il s’agit d’une spécification de description d’une API HTTP en utilisant des fichiers au format YAML. La syntaxe est simple et les possibilités d’extension très nombreuses.
Voici un extrait (réel) de la documentation d’une partie de l’API mailbox :
yaml
/forwards:
/{domain}:
displayName: Manage your forwarding addresses
description: |
Forwarding addresses make it possible to redirect mail from
one or more of your domain’s email addresses to an external
address. Learn more on the documentation.
securedBy: [lib.api-key]
is: [lib.restricted]
uriParameters:
domain:
type: lib.Domain
description: Domain name.
get:
displayName: List forwarding addresses
description: |
This route returns a paginated list of forwarded email addresses
on the given domain.
is: [lib.paginated]
queryString:
type: lib.email.ForwardListFilters
responses:
200:
body:
application/json:
type: lib.email.ForwardList
RAML permet de définir des directives réutilisables permettant de ne pas répéter partout les mêmes descriptions. Dans l’exemple ci-dessus, la route
`GET /forwards/{domain}` est paginée (indiqué par `is: [lib.paginated]`) ; cette directive ajoute automatiquement les définitions de pagination (les arguments reçus et les nouveaux en-têtes HTTP de la réponse).
Après quelques tests, nous avons pu valider que les format fonctionnait pour nos besoins et nous l’avons mis en place pour la documentation de nos API internes.
Une passerelle
Comme indiqué en introduction, nous avons eu besoin d’une passerelle pour pouvoir faire transiter les requêtes des utilisateurs vers le bon service et, éventuellement, modifier les données de celles-ci (ou des réponses). Il existe un grand nombre d’outils pour mettre en place une passerelle HTTP mais très peu permettent d’agir sur les requêtes et les réponses (données comprises).
Notre choix s’est rapidement porté sur Express Gateway. Cette application NodeJS dispose d’un certain nombre de modules complémentaire dont un pour faire proxy. Au moment du développement, il a fallu le réécrire pour permettre la modification des données au cours de leur transmission.
La transformation des données se fait en transmettant une structure de données correspondant à la requête ou la réponse HTTP et en appliquant une structure décrivant la transformation. L’exemple suivant montre une définition de transformation telle que nous pouvons en rencontrer dans notre code :
json
{
"rename": {
"headers.x-total-count": "total-count"
},
"alter": "$.apply('body.*', x => {x.href = $.url(x.source);});"
}
Cette définition (d’une réponse) indique que nous souhaitons faire deux choses :
- Renommer l’en-tête « x-total-count » en « total-count »
- Ajouter une clé `href` à chaque élément de la liste
Le code JavaScript dans `alter` est exécuté dans une *sandbox* et n’a accès qu’à la variable `$` (qui contient les informations de l’objet à transformer, et quelques méthodes utilitaires).
Après un peu (ou beaucoup) de développement, nous avions une passerelle prête à l’emploi ou nous pouvions, pour chaque route, indiquer comment nous souhaitions transformer ce que la passerelle transmet ou les réponses qu’elle reçoit. Et nous avions un format de documentation. La suite logique était donc d’unifier les deux.
Une passerelle pilotée par la documentation
Comme nous l’avons dit précédemment, nous souhaitions une documentation parfaitement synchronisée avec l’API. C’est généralement et logiquement ce que tout le monde veut.
Il existe deux façons d’arriver à ce résultat :
- Un outil analyse le code d’un programme et en extrait une documentation.
- La documentation définit le comportement du programme.
Dans notre cas, le programme est en fait la configuration de la passerelle. Ceci rend la première option assez compliquée, d’autant plus que la configuration de Express Gateway est assez bavarde (comprendre *pénible à écrire*).
Par contre, alors que la seconde option est complexe quand on parle de vrai code, c’est parfaitement envisageable dans notre situation. Il s’agit ni plus ni moins de traduire un format vers une autre (de RAML vers la configuration de la passerelle). La documentation fournit déjà presque toutes les informations nécessaires (le chemin, les méthodes, les réponses possibles, etc.). Le reste, nous pouvons le faire avec des extensions RAML.
Nous avons donc mis en place une extension à Express Gateway pour pouvoir charger un fichier RAML au démarrage, le parser et générer la configuration finale de la passerelle.
Côté RAML, nous avons défini quelques extensions pour indiquer quel service doit être utilisé pour une section donnée, et comment modifier les requêtes et les réponses.
En reprenant l’illustration précédente, nous obtenons maintenant ceci :
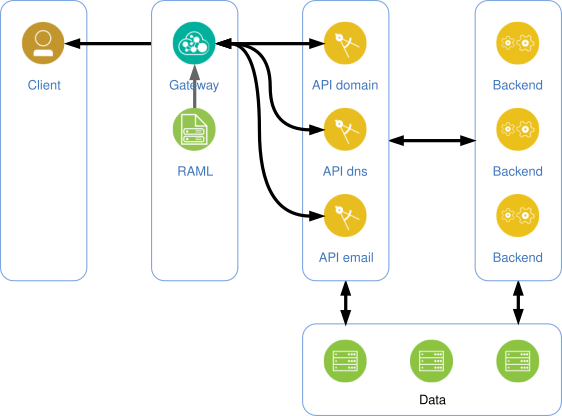
Voici à quoi ressemble l’exemple précédent, en contexte dans son fichier RAML :
yaml
/forwards:
/{domain}:
get:
responses:
200:
body:
application/json:
(x-proxy-actions):
rename:
headers.x-total-count: total-count
alter: |
$.apply('body.*', x => {
x.href = $.url(x.source);
});
On reconnaît ici le premier exemple RAML donné précédemment. Il s’agit d’un extrait du fichier surchargeant la documentation vue auparavant. Les parties `(x-…)` sont des extensions RAML qui sont interprétées par le parseur et utilisées pour générer la configuration de la passerelle.
Dans les faits, notre API publique utilise donc directement la documentation pour se configurer, avec pour conséquence que le comportement de la passerelle est **toujours** synchronisé avec ce qui est présent.
Variables et validation de données
Ici nous appelons « variables » toutes les données de requêtes et réponses traitées par la passerelles (paramètre d’URL, données JSON, en-têtes).
Hormis une validation de syntaxe (JSON d’une requête par exemple), la passerelle ne valide pas les variables par rapport au schéma RAML correspondant à une requête ou une réponse. Nous avons choisi de laisser cette tâche aux services cibles.
Cependant, la passerelle se charge d’une étape cruciale ; elle filtre les données. Par exemple, si le schéma indique qui peut recevoir les paramètre `A`, `B` et `C` dans l’URL, et qu’un client envoie le paramètre `D`, ce dernier ne sera jamais transmis au service cible.
De la même manière, uniquement les variables spécifiées dans le schéma d’une réponse seront retournées au client de l’API.
Ceci nous permet de faire évoluer les schémas de nos services sans automatiquement tout exposer du côté de l’API publique. C’est un peu plus de travail de notre côté mais nous y gagnons en contrôle.
Feuille de route
Dans les mois à venir, nous allons progressivement ajouter des services et fonctionnalités manquantes à l’API publique. Bien qu’étant en état de test (beta), nous nous efforçons de ne pas introduire de régression lors des mises à jour que nous effectuons.
Enfin, concernant l’actuelle API XML/RPC, nous n’allons pas la fermer immédiatement, vous laissant le temps de migrer vos outils vers la nouvelle API, à votre rythme.
N’hésitez pas à nous faire part de toutes vos remarques si vous utilisez la nouvelle API publique en nous contactant sur le formulaire dédié.