Postmortem regarding the Network Incident from September 15, 2020 on IAAS and PAAS FR-SD3, FR-SD5, and FR-SD6

During scheduled maintenance aimed at replacing network equipment in the FR-SD5 datacenter, an error in the architecture and configuration caused two distinct service interruptions on PaaS and IaaS in the FR-SD3, FR-SD5, and FR-SD6 datacenters during the day.
First incident
- 09:22 UTC: Layer 2 network loop introduced
- 09:30 UTC: Network loop removed, network infrastructure stabilized
Until 13:26 UTC, some PaaS and IaaS instances were not functioning correctly.
Second incident
- 14:15 UTC: Second layer 2 network loop introduced
- 14:26 UTC: Second network loop removed
Consequences
This incident had two consequences:
- During the network loops, access to services was disrupted
- Some VMs saw their disk(s) go read-only to avoid data corruption, following the network loops. Because of this, the VMs won’t work correctly until a filesystem check has been performed.
Postmortem: what happened?
Why were hosting services unavailable, and side effects introduced, over the course of September 15?
A layer 2 network loop was introduced during a network maintenance.
Why was a network loop introduced?
Because of an incorrect assumption regarding the architecture that we have on our datacenters: FR-SD3, FR-SD5, and FR-SD6. The architecture design for these datacenters was conceived so that they would be independent.
They are not supposed to have any links between them. In fact, having an extended layer 2 network between multiple datacenters is risky: problems with the layer 2 can be amplified, with larger impacts, and it’s also much easier to introduce network loops. Thus, during our scheduled maintenance, the replacement of the aforementioned equipment by technical teams completed the extended layer 2 and created a loop.
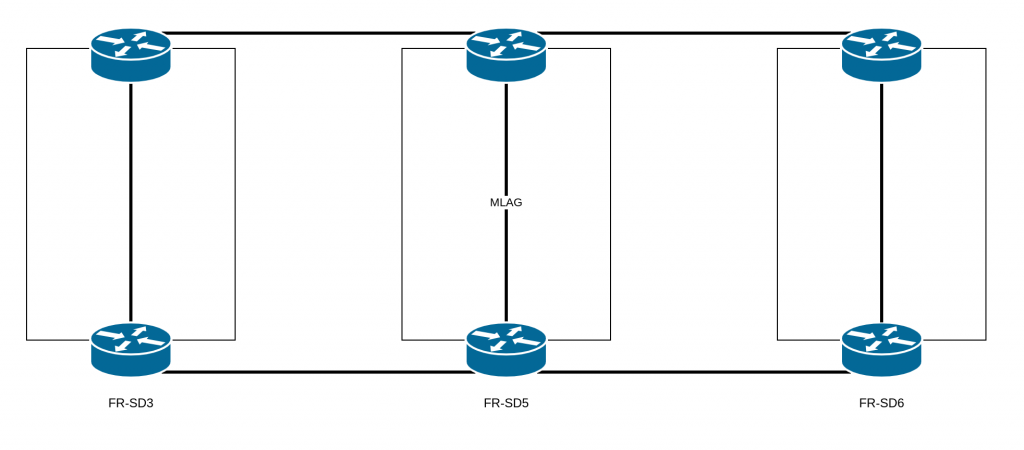
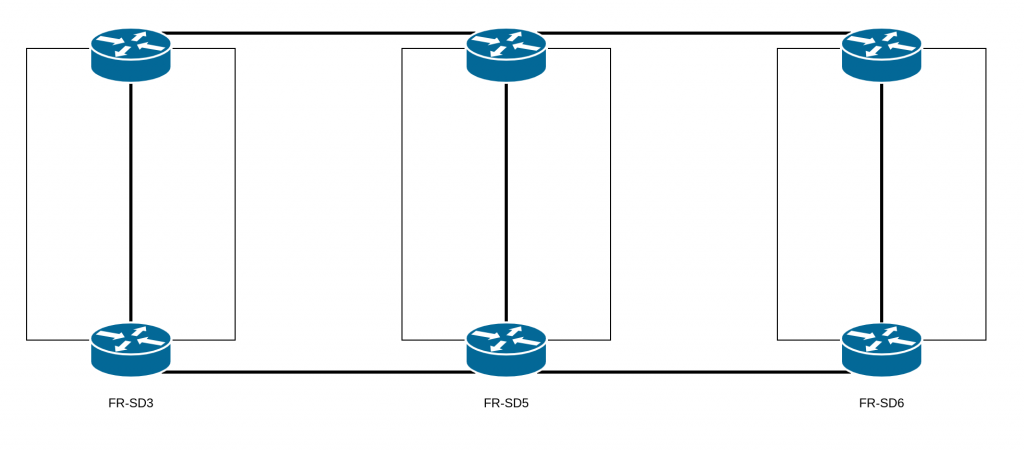
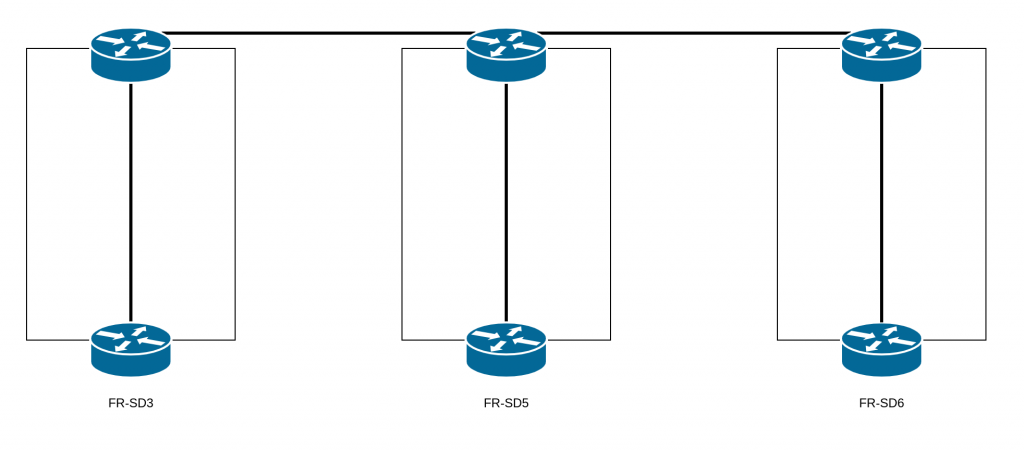
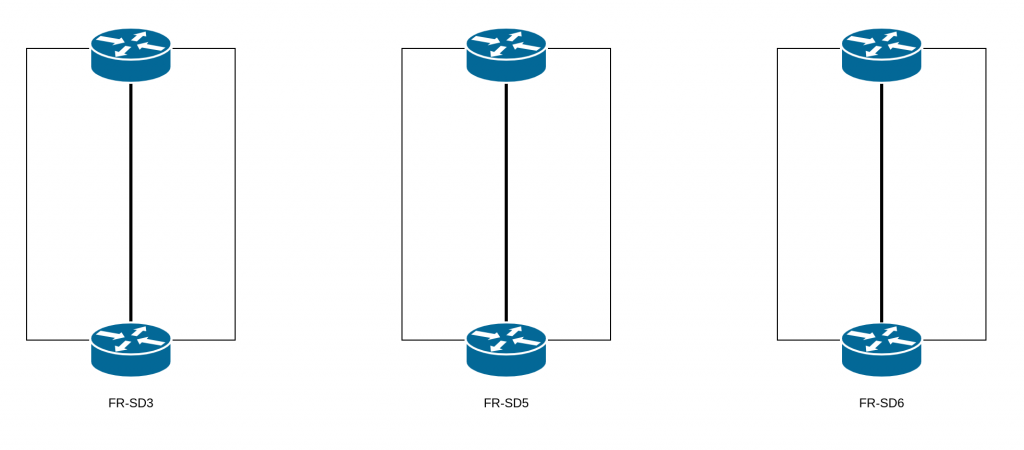
Why, then, was there an extended layer 2 network between these datacenters?
During the migration of our old datacenter (FR-SD2), some design constraints forced us to establish this extended layer 2 to allow for IaaS and PaaS instances to contact their network gateways.
Why is this extended layer 2 network still there?
Because we haven’t finished centralizing customers’ instances on a single datacenter.
How did you neglect the importance of the extended layer 2 network between these datacenters?
Preparation for the maintenance was done mostly by looking at the architecture documentation, and we failed to pay as much attention as we should have to this temporary exception.
Short term, to finish the network maintenance
- Completion of the migration while taking the restrictions of the extended L2 network into account.
- Migration of the instances still using this extended L2 network so it can be removed cleanly.



