
On February 16, we announced that we had completed the migration of our Simple Hosting service from our former data center, FR-SD2.
We are now fully operational on new data centers with a better network architecture and new machines. That is to say, on a new, more uniform system with greater stability that allows us to offer you higher performing hosting services
The process of migrating Simple Hosting instances to their new home was, for some customers, marked by performance problems on storage units which in turn impacted the availability of their sites. And even with added support from our tech team, our Customer care response times were still quite delayed, causing frustration for many of the customers who were impacted.
Today we’ll be giving you a look at the current status and analyzing the problems that we’ve run into and resolved through the several Simple Hosting instance migration phases.
Summary of migration plan:
- October 4, 2017: FR-SD3 data center opened
- November 13, 2017: Simple Hosting instance migration to FR-SD3 begins
- December 21, 2017: FR-SD5 opens, migration to this data center begins
- January 16, 2018: FR-SD6 opens, migration to this data center begins
- February 15, 2018: Migration of all Simple Hosting customers to be completed by this date
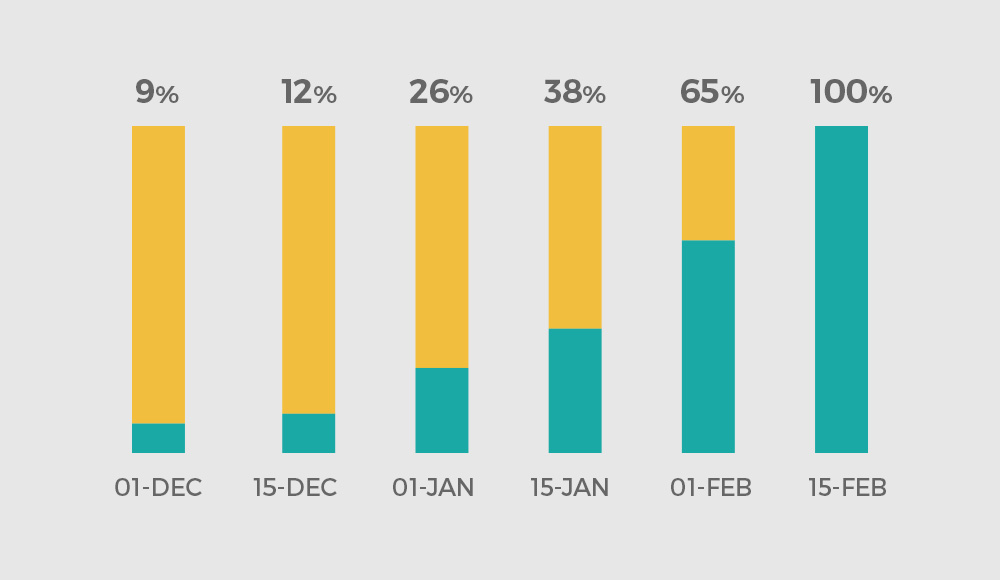
What caused the problem
Performance problems we encountered throughout the migration process are largely due to a crucial misestimation in density calculation and a lack of exhaustive real-world testing.
What’s more, over the course of the past ten years, our old platform had undergone several upgrades and major changes, which meant that many fixes deployed on-the-fly were poorly documented, preventing us from being able to fully anticipate behavior during the migration.
Consequences on performance on the Simple Hosting Platform
Websites unavailable (503 error)
In December, when we had only about 20% of instances migrated, some customers started to report some slowness or errors following migration.
Certain of these were due to the change in data center architecture. The new data center architecture deployed on FR-SD3, FR-SD5, and FR-SD6 allows us a lot more flexibility to add new language versions and database versions, develop new features, and improve user experience. This was the foundation we’ll build on as we continue to improve our service.
On migration, though, certain incompatibilities between the old and the new architecture caused some people problems. So we adjusted the behavior of the new data centers to match that of the old one, FR-SD2. For example, we installed some PHP libraries missing on the new data centers and we also had to request that certain customers make some adjustments when we were unable to make the necessary adjustments ourselves (when such adjustments would compromise security, for example).
These performance problems in turn led to slow downs and generated 503 errors, generally meaning that a web accelerator had not gotten a response from the instance in question in time.
We diagnosed this problem as being due largely to overloaded storage units which were no longer able to execute operations in a reasonable amount of time. After becoming aware of this issue, we tried to adjust their configuration a first time and failed.
Then we tried to reduce exchanges between machines where instances are executed as well as those where customer data are stored, in order to reduce the load on storage units and delegate certain tasks to the machines hosting the instances.
A problem at the level of the kernel configuration of the machines, resulting in packet loss between accelerators and machines, was also at this point identified and corrected. We were thereby able to considerably reduce the number of 503 errors produced.
It took us a few days nonetheless to implement and test all these changes, which were deployed on all data centers starting December 28, allowing us to reduce the number of exchanges between machines and storage units.
Slower sites
We continued to run into certain performance limitations on the storage units into January
That’s why at the beginning of January we put monitoring tools into place allowing us to more precisely track the load on the machines hosting our customers’ data. This allowed us to isolate the instances generating the most read/write activity on each storage unit.
With this information we were then able to better allocate resources so that each storage unit performed better and the more active instances ceased impacting the performance of other instances. For example, we isolated certain WordPress plugins that, poorly configured, were backing the entire instance far too often.
We are still monitoring the load related to these instances and will make adjustments as necessary.
Beyond that, starting January 19, we applied several fixes that allowed us to improve performance of the software serving customer data on system machines.
Finally, on February 5, we added further storage units to each data center. This allowed us to better distribute the load and finalize the migration of the remaining instances on Fr-SD2.
Abnormally long response times in Customer care
Despite all attempts to anticipate the added support ticket volume by recruiting additional support agents, it wasn’t possible to handle all support requests in as timely a manner as we usually do and we are sorry to anyone impacted.
Several unrelated incidents in January and February impacted some of the services on these data centers and while we were able to react quickly to these as they arose, they also generated a greater volume of tickets.
Return to normal
We are expecting to receive shortly new material enabling us to add even more storage units to each of our data centers and thereby further stabilize performance on our platform.
As of today, barring some extraordinary circumstance, the situation has returned to normal for all our customers and we are actively monitoring activity on all instances in order to detect any and all future performance issues before they begin to impact all instances hosted on the same storage unit.
If your instance is one of the handful of exceptions, it’s possible that we will move it from one storage unit to another. If that happens, you will notice brief downtime on your site.
The volume of support tickets is also stabilizing and we hope to be able to return to the same service levels you have normally experienced during the month of March.
We would like to additionally thank you for your patience and for continuing to choose Gandi during this difficult transition. We’re still developing and advancing our platform and expect to introduce exciting new developments soon.
Tagged in Simple Hosting


