
Since early January, our hosted DNS service LiveDNS has been hosted on an anycast platform more distributed than we could ever achieve before. We’ve been slowly migrating customers from our old infrastructure to the new one over the last few months and the service is now hosted on what we call internally “nanopops”. This allowed us to bring service to new locations we’ve never been before, especially places closer to our customers.
The service is now hosted by a number of small independent servers in various locations (Paris, Luxembourg, Tokyo, London, Amsterdam, Berlin, Prague, Ashburn, Los Angeles). Because running traditional infrastructure with backbone networks and routers in various locations around the world would come at a very large cost and would limit our deployment size, we came up with an innovative way to boot and manage globally distributed servers. The internet being a reliable network, we decided to instead just rely on it and boot our servers over the Internet.
We have shipped servers to a bunch of different locations either to PoP (Points of presence) we manage or partners that provide us network service in the location. The upstream network will give us an interconnection IP for our two networks to connect and exchange traffic. When a server is racked, plugged, and powered it will run a small bootloader, configure network, and connect back to our infrastructure. This infrastructure will provide a Linux kernel and a system image for the server to run.
Once booted, the server will start syncing the database from the provisioning server, start the DNS server and announce our service IPs with BGP.
This comes with new challenges regarding automation and security, but we stand on the shoulders of giants here and I’d like to describe how we did it in this blog post.
Booting over the internet
Our bootloader, the first bits of code that run on our servers when they boot, is based on iPXE. The bootloader would fetch a boot configuration from one of our provisioning servers, download a Linux kernel as well as a system image. iPXE provides a couple of security features like network security and payload signature.
All the requests sent by the bootloader are authenticated by TLS with a client certificate and all payloads are signed by an offline key available on our build servers. Should one or the other fail, the bootloader will just keep retrying on a different provisioning server.

This simple and reliable bootloader allows us to upgrade servers, operating systems, and the kernel very easily. Just reboot and it comes back updated.
Building a system image
At Gandi, we run mostly on Debian systems and configure our platforms with Puppet to handle configuration management. We have become quite efficient with both and wanted to keep the same tools.
Servers usually run from a disk and get updated regularly locally. Should a problem occur, we either send a technician to the server or use out-of-band network equipment to diagnose the issue, and fix it locally. In this platform, because all servers would be placed in very remote locations, we preferred to not rely on any of this. Should something happen, the server should reboot and start-over. Because service is distributed with anycast BGP, traffic will get redirected to a different location without any service impact.
As a consequence, the system image we boot is stateless, it comes with kernel, userland, software and configuration. No manual operation is necessary when a server boots. Building those images reliably, ensuring consistency and reproducibility is not an easy task, and we chose to leverage Puppet which is based on the idempotence principle. Usually, a Puppet catalog is compiled on a puppet-server and then applied by a puppet-agent, the catalog describes the perfect/expected state, and the agent converges the running system to the expected state. Applying twice the same catalog yields the same result. This is a good property to base a build system on as it provides consistency and reproducibility.

Because we’re building a stateless image, we have no puppet server in this infrastructure, but to reuse our Puppet codebase, our build script will build a static Puppet catalog. This catalog includes the software versions and configuration expected for a server in production, we will then use debootstrap to obtain a simple basesystem from Debian repositories. Next build step is to run a puppet-agent using the catalog inside a Linux container mimicking the production environment as much as possible. This installs all required software (DNS server, database replication software, monitoring, …) inside the Linux container along with the configuration.
Just extract the disk resulting from the puppet-agent to a cpio image and you get a runnable initramfs you can start on the target computer!
Our last build step is to sign the image with RSA keys for iPXE to verify. This ensure integrity checks on the image and ensures it can not be altered during transport nor on disk on the provisioning server.
The resulting system is stateless, runs fully from RAM and is cryptographically verified. Should something bad happen the server just reboots and starts over.
This build system has served us well and we’ve been able to upgrade software, userland, and kernel reliably over the last few months of production.
DNS service replication on a remote server
Once booted, the remote server connects again to our provisioning servers, grabs a fresh copy of our database and then listens for updates.
Again, all those communications are encrypted with the same keys the server used to boot in the first place.
We measured the latency of updates from our API to a nanopop at under 100ms + network latency to the pop. The farthest server from our datacenter being Tokyo at 250ms, the maximum latency for a DNS update to be deployed globally on our infrastructure is kept under half a second.
(Note: latency is actually 13ms + network latency, but I’m being conservative here.)
Getting a state on the server
Although a stateless system is a blessing to work with, being very reliable in production, it is sometimes useful to keep a state on a server. We keep a local copy of the DNS database on the server stored on SSD drives. This allows us to lower the service time when we reboot to upgrade servers. The system image will mount or format SSD drives, setup encryption, and just reuse the database available locally after reboot.
Better service for our customers and yours
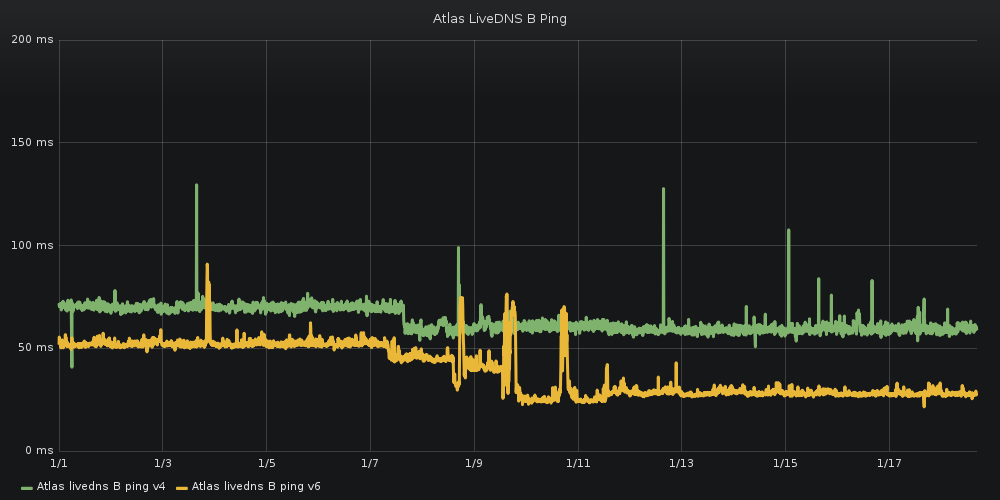 The average latency for 15 Atlas probes worldwide drops by 15 milliseconds
The average latency for 15 Atlas probes worldwide drops by 15 milliseconds
We’ve been monitoring the deployment of our nanopops infrastructure with RIPE Atlas probes and we saw a lot of improvement on latency for end-users. Lowering latency improves performance for all users of the LiveDNS platform. Anyone who queries for your domain names will get the response with the IP address of your website, email servers, and other services more quickly. Distributing the platform also provides better resiliance against DDoS attacks. The road ahead is still long, but we’re excited about it!
Arthur is a system engineer at Gandi based in our San Francisco office. If you have any questions, feel free to reach out on Twitter @baloose.
Tagged in Domain names


